This year's Flock was help in Krakow, Poland, from 2nd to 5th August. /me, and Sayan
started our journey on 30th from Pune, and we reached Krakow finally on 31st
afternoon. Ratnadeep joined us from the Frankfurt. Patrick was my roommate this
time, he reached few hours after we reached.
Day -1

Woke up early, and started welcoming people near the hotel entrance. Slowly the
whole hotel was filling up with Flock attendees. Around noon, few of us decided
to visit the Oskar Schindler's Enamel
Factory.
This is place I had in my visit list for a long time (most of those are
historical places), finally managed to check that off. Then walked back to city
center, and finally back to the hotel.
Started meeting a lot more people in the hotel lobby. The usual stay up till
late night continued in this conference too. Only issue was about getting up
early, somehow I could not wake up early, and write down the daily reports as I
did last year.
Day 0
Managed to reach breakfast with enough time to eat before the keynote starts.
Not being able to find good espresso was an issue, but Amanda later pointed me
to the right place. I don't know how she manages to do this magic everytime,
she can really remove/fix any blocker for any project :)

Received the conference badge, and other event swags from registration desk.
This one is till date the most beautiful badge I have seen. Mathew gave his
keynote on "The state of Fedora". Among many other important stats he shared,
one point was really noticeable for me. For every single Red Hat employee who
contributes to Fedora, there are at least two contributors from the community.
This is a nice sign of a healthy community.
After the keynote I started attending the hallway tracks as usual. I went to
this conference with a long of topics I need discuss with various people. I
managed to do all of those talks over the 4 days of the event. Got tons of
input about my work, and about the project ideas. Now this is the time to make
those suggestions into solid contributions.
Later I went into the "The state of Fedora-infra" talk. This was important to
me personally, as this gives as easy way to revisit all the infrastructure work
going on. Later in the day I attended Fedora Magazine, and university outreach
talk.
In the evening there was "Tour of Krakow", but Fedora Engineering team had a
team dinner. As this is only time when all of us meet physically. Food was once
again superb.
Day 1
As I mentioned before it was really difficult to wake up. But somehow managed
to do that, and reached downstairs before the keynote started. Scratch was
mentioned in the keynote as tool they use. Next was usual hallway talks, in the
second half I attended the diversity panel talk, and then moved to Pagure talk.
I knew that there were a huge list new cool features in Pagure, but learning
about them directly from the upstream author is always a different thing.
Pingou's slides also contained many friends' names, which is always a big happy
thing :)
My talk on Testing containers using Tunir
was one of the last talk of the day. You can go through the whole presentation,
and if you want to see any of the demos, click on those slides. That will open
a new tab with a shell console, type as you normally type in any shell (you can
type any char), and press Enter as required. I use Tunir to test my personal
containers which I run on production. This talk I tried to various such use
cases.
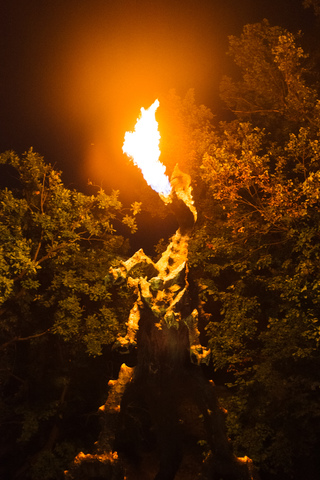
At night we went out the river cruising. Before coming back few of us visited
the famous Wawel Dragon.
I also met Scot Collier for
the first time. It is always to meet people with whom you work regularly over internet.
Day 2
It started with lightening talks. I spoke for few minutes about dgplug summer
training. You can find the list of talks
here. After this
in the same room we had "Meet the FAmSCo" session. I managed to meet Gerold,
Kanarip, Fabian after 9 years in this Flock. Christoph Wickert took notes, and
discussed the major action items in last week's FAmSCo IRC meeting too. Next I
attended "Infrastructure workshop", after that as usual hallway tracks for me.
I was looking forward to have a chat with Dodji Seketeli about his, and Sinny's
work related about ABI stability. Later at night few of us managed to stay up
till almost 5AM working :)
Day 3
Last day of Flock 2016. Even after the early morning bed time, somehow managed
to pull myself out of the bed, and came down to the lobby. Rest of the day I
spent by just talking to people. Various project ideas, demos of ongoing work,
working on future goals.
Conclusion
Personally I had a long list of items which I wanted to talk to various people.
I think I managed to cross off all of those. Got enough feedback to work on
items. In the coming days I will blog on those action items. Meanwhile you can view
the photos from the event.