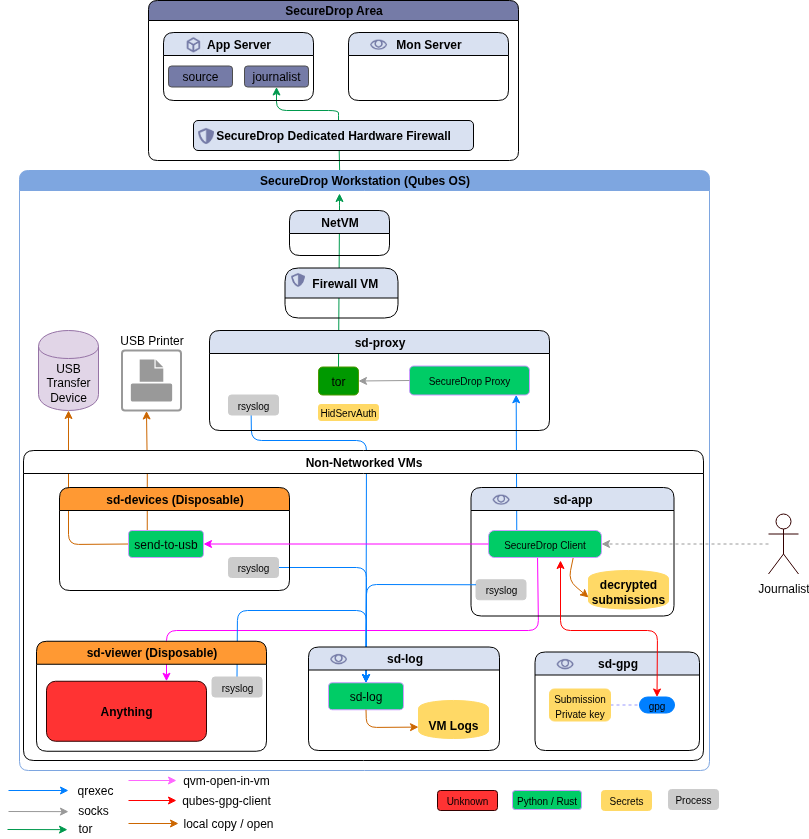
Using hexchat on Flatpak on Qubes OS AppVM
Flatpak is a system for building, distributing, and running sandboxed desktop applications on Linux.
It uses BubbleWrap in the low level to do the actual sandboxing. In simple terms,
you can think Flatpak as a as a very simple and easy way to use desktop applications in containers (sandboxing). Yes, containers,
and, yes, it is for desktop applications in Linux. I was looking forward to use
hexchat-otr in Fedora, but, it is not packaged in Fedora. That is what made me setup an AppVM for the same using flatpak.
I have installed the flatpak package in my Fedora 29 TemplateVM. I am going to use that to install Hexchat in an AppVM named irc.
Setting up the Flatpak and Hexchat
The first task is to add flathub as a remote for flatpak. This is a store where upstream developers package
their application and publish.
flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
And then, I installed the Hexchat from the store. I also installed the version of the OTR plugin required.
$ flatpak install flathub io.github.Hexchat
<output snipped>
$ flatpak install flathub io.github.Hexchat.Plugin.OTR//18.08
Installing in system:
io.github.Hexchat.Plugin.OTR/x86_64/18.08 flathub 6aa12f19cc05
Is this ok [y/n]: y
Installing: io.github.Hexchat.Plugin.OTR/x86_64/18.08 from flathub
[####################] 10 metadata, 7 content objects fetched; 268 KiB transferr
Now at 6aa12f19cc05.
Making sure that the data is retained after reboot
All of the related files are now available under /var/lib/flatpak. But, as this is an AppVM, this will get destroyed
when I will reboot. So, I had to make sure that I can keep those between reboots. We can use the Qubes bind-dirs for this in the TemplateVMs,
but, as this is particular for this VM, I just chose to use simple shell commands in the /rw/config/rc.local file (make sure that the file is executable).
But, first, I moved the flatpak directory under /home.
sudo mv /var/lib/flatpak /home/
Then, I added the following 3 lines in the /rw/config/rc.local file.
# For flatpak
rm -rf /var/lib/flatpak
ln -s /rw/home/flatpak /var/lib/flatpak
This will make sure that the flatpak command will find the right files even after reboot.
Running the application is now as easy as the following command.
flatpak run io.github.Hexchat
Feel free to try out other applications published in Flathub, for example, Slack or the Mark Text