Tracking my phone's silent connections
My phone has more friends than me. It talks to more peers (computers) than the number of human beings I talk on an average. In this age of smartphones and mobile apps for A-Z things, we are dependent on these technologies. However, at the same time, we don’t know much of what is going on in the computers equipped with powerful cameras, GPS device, microphone we are carrying all the time. All these apps are talking to their respective servers (or can we call them masters?), but, there is no easy way to track them.
These questions bothered me for a long time: I wanted to see the servers my phone is connecting to, and I want to block those connections as I wish. However, I never managed to work on this. A few weeks ago, I finally sat down to start working to build up a system by reusing already available open source projects and tools to create the system, which will allow me to track what my phone is doing. Maybe not in full details, but, at least shed some light on the network traffic from the phone.
Initial trial
I tried to create a wifi hotspot at home using a Raspberry Pi and then started
capturing all the packets from the device using standard tools (dumpcap) and
later reading through the logs using Wireshark. This procedure meant that I
could only capture when I am connected to the network at home. What about when I
am not at home?
Next round
This time I took a bit different approach. I chose algo to create a VPN server. Using WireGuard, it became straightforward to connect my iPhone to the VPN. This process also allows capturing all the traffic from the phone very easily on the VPN server. A few days in the experiment, Kashmir started posting her experiment named Life Without the Tech Giants, where she started blocking all the services from 5 big technology companies. With her help, I contacted Dhruv Mehrotra, who is a technologist behind the story. After talking to him, I felt that I am going in the right direction. He already posted details on how they did the blocking, and you can try that at home :)
Looking at the data after 1 week
After capturing the data for the first week, I moved the captured pcap files into my computer. Wrote some Python code to put the data into a SQLite database, enabling me to query the data much faster.
Domain Name System (DNS) data
The Domain Name System (DNS) is a decentralized system which helps to translate the human memory safe domain names (like kushaldas.in) into Internet Protocol (IP) addresses (like 192.168.1.1 ). Computers talk to each other using these IP addresses, we, don’t have to worry to remember so many names. When the developers develop their applications for the phone, they generally use those domain names to specify where the app should connect.
If I plot all the different domains (including any subdomain) which got queried at least 10 times in a week, we see the following graph.
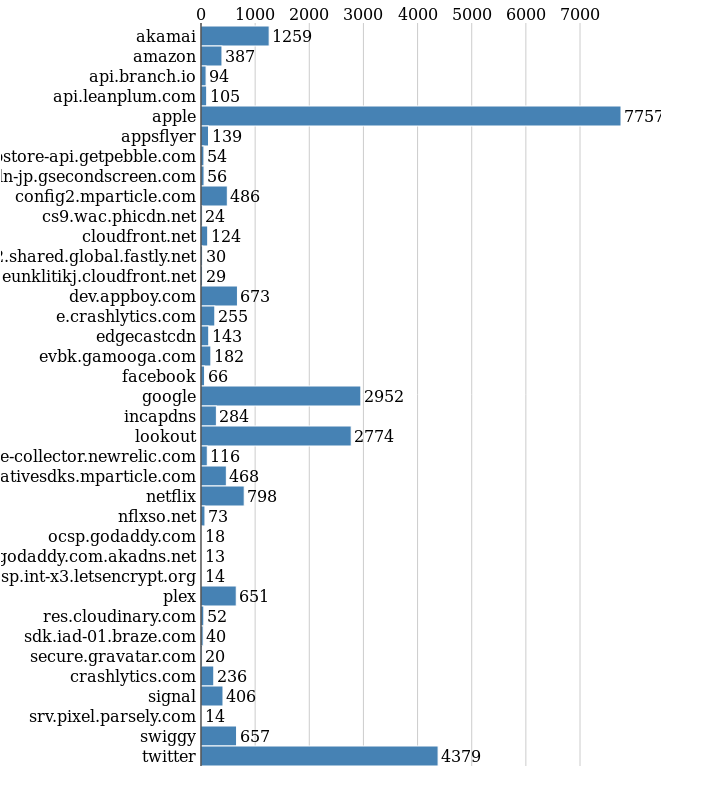
The first thing to notice is how the phone is trying to find servers from Apple, which makes sense as this is an iPhone. I use the mobile Twitter app a lot, so we also see many queries related to Twitter. Lookout is a special mention there, it was suggested to me by my friends who understand these technologies and security better than me. The 3rd position is taken by Google, though sometimes I watch Youtube videos, but, the phone queried for many other Google domains.
There are also many queries to Akamai CDN service, and I could not find any easy way to identify those hosts, the same with Amazon AWS related hosts. If you know any better way, please drop me a note.
You can see a lot of data analytics related companies were also queried.
dev.appboy.com is a major one, and thankfully algo already blocked that domain
in the DNS level. I don’t know which app is trying to connect to which all
servers, I found about a few of the apps in my phone by searching about the
client list of the above-mentioned analytics companies. Next, in coming months,
I will start blocking those hosts/domains one by one and see which all apps stop
working.
Looking at data flow
The number of DNS queries is an easy start, but, next I wanted to learn more about the actual servers my phone is talking to. The paranoid part inside of me was pushing for discovering these servers.
If we put all of the major companies the phone is talking to, we get the following graph.

Apple is leading the chart by taking 44% of all the connections, and the number is 495225 times. Twitter is in the second place, and Edgecastcdn is in the third. My phone talked to Google servers 67344 number of times, which is like 7 times less than the number of times Apple itself.

In the next graph, I removed the big players (including Google and Amazon).
Then, I can see that analytics companies like nflxso.net and mparticle.com
have 31% of the connections, which is a lot. Most probably I will start with
blocking these two first. The 3 other CDN companies, Akamai, Cloudfront, and
Cloudflare has 8%, 7%, and 6% respectively. Do I know what all things are these
companies tracking? Nope, and that is scary enough that one of my friend
commented “It makes me think about throwing my phone in the garbage.”
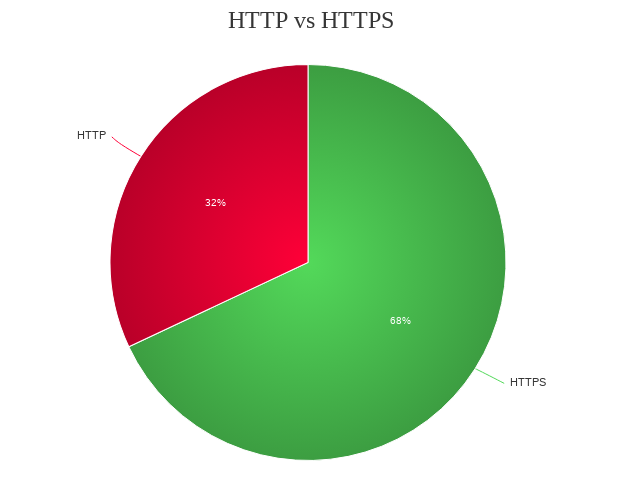
What about encrypted vs unencrypted traffic? What all protocols are being used? I tried to find the answer for the first question, and the answer looks like the following graph. Maybe the number will come down if I try to refine the query and add other parameters, that is a future task.
What next?
As I said earlier, I am working on creating a set of tools, which then can be deployed on the VPN server, that will provide a user-friendly way to monitor, and block/unblock traffic from their phone. The major part of the work is to make sure that the whole thing is easy to deploy, and can be used by someone with less technical knowledge.
How can you help?
The biggest thing we need is the knowledge of “How to analyze the data we are capturing?”. It is one thing to make reports for personal user, but, trying to help others is an entirely different game altogether. We will, of course, need all sorts of contributions to the project. Before anything else, we will have to join the random code we have, into a proper project structure. Keep following this blog for more updates and details about the project.
Note to self
Do not try to read data after midnight, or else I will again think a local address as some random dynamic address in Bangkok and freak out (thank you reverse-dns).